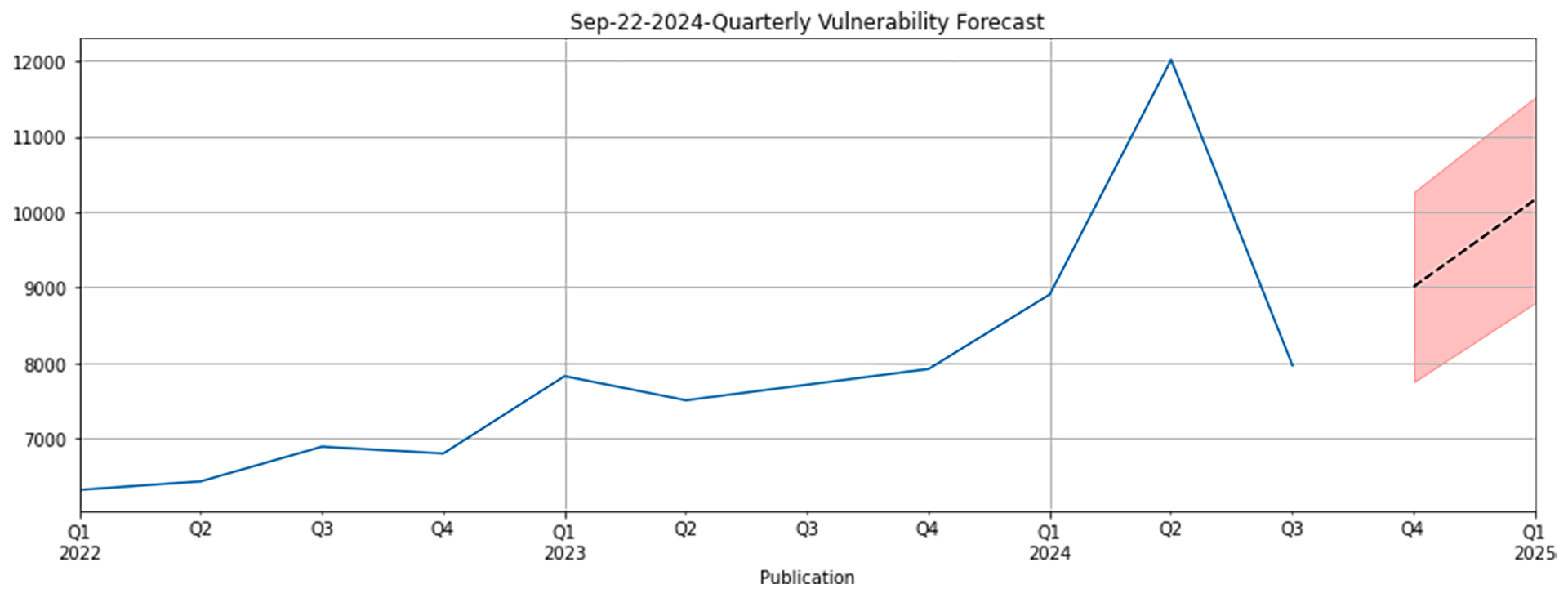
The graphic below shows an interesting anomaly, in that there seems to be a large jump in Q2 publications, that was not there earlier in the year. There have been a lot of changes in the CVE program this year, and how MITRE and NVD manage the processes, but this is still a surprise to me. I checked our Q2 forecast and the Q3 retrospective of it, and I can clearly see at the time of that blog that there were not 12k vulnerability publications in Q2. This suggests something has been backdated, and I will dig into that further and present something at the end of year forecast to explain the retrospective jump in a quarter.
So how did we do in Q3, prediction?
In Q3 7965 vulnerabilities were published by NVD, but we predicted 8841 +/- 608 with a step two forecast. That means instead of using the new data at the end of Q2, we relied on a forecast that itself was based on the numbers of the forecast before it. Now clearly this forecast was wrong and outside the confidence intervals and off by about 9%.
Believe it or not, I’m pretty pleased with that because our usual margin is 8%, and to be off by 1% when using a second step is not bad. We are experimenting now with our second step forecasts accuracy which even when we’re wrong gives me great hope.
It’s worth saying when you design a forecast you have to make some deliberate choices, such as how often you want to be wrong. For example, I could forecast and number and tell you it is plus or minus 1000%. Clearly, the margins are wide enough to keep me always correct, but less useful to those who might need to know the variance for real world problems. Thus, you try to balance the width of the margins, by how often they will turn out to be wrong. We settled on a forecast that should be wrong 1 out of 20 times.
The deeper story though is that step two forecasting is within orders of magnitude correct, meaning if we can handle the uncertainty, we can use those as effectively as the step one forecasts. All of this kind of thing is heavily discussed at our upcoming conference. Come join us and make these forecasts even better. I know there’s plenty to do to make them more useful, and more accurate, and I welcome feedback from the community on how to do it.
FIRST runs a blog open to members and invited guest authors. It publishes contributions relevant to incident responders. Articles should focus on general topics interesting to members. It will not be used to promote individual organisations, products or services. If you are interested in contributing, please get in touch with first-blog@first.org.
Learn more about the Forum of Incident Response and Security Teams through regular blog posts about our organization, events and other programs. Questions or comments? Contact first-press@first.org.