In calendar year 2024 we had another record breaking 40,704 CVEs published. That in itself is a significant achievement for the women and men who support, process, and publish CVEs. We all depend on accurate and useful vulnerability information to do a significant amount of our work, so I want to begin this blog by calling out their great work.
Secondly, it blew everyone’s forecasts from 2024 out of the water. I will leave others to comment on their own forecasts, but I will do a deep dive about my own forecasts for FIRST.org here.
The short and blunt analysis is that we underpredicted by 6054 CVEs this year.
We had an undershoot in our prediction by a large enough number that it causes us to rethink our approach. So how do we define a failed forecast, one worthy of deep dive and reflection?
Any reasonable person could probably agree that a point forecast (one with only a single number) is unlikely to be correct. That’s why we publish an expected number and a upper and lower confidence interval. A range of values if you like, with the minimum and maximum being less likely, but still very possible.
A more detailed view is that the actual number was outside our confidence interval, or our “max for the year”. All forecasting we do assigns a 5% chance that the forecast will above the max, and another 5% it will be below the minimum. So we know that 1 out of ten years our forecasts will be outside this range. However we also know that in most years the number of vulnerabilities published breaks last year’s record, so we’re more likely to be above than below.
So is this “one of those years” or a more important event that should cause us to reconsider our approach?
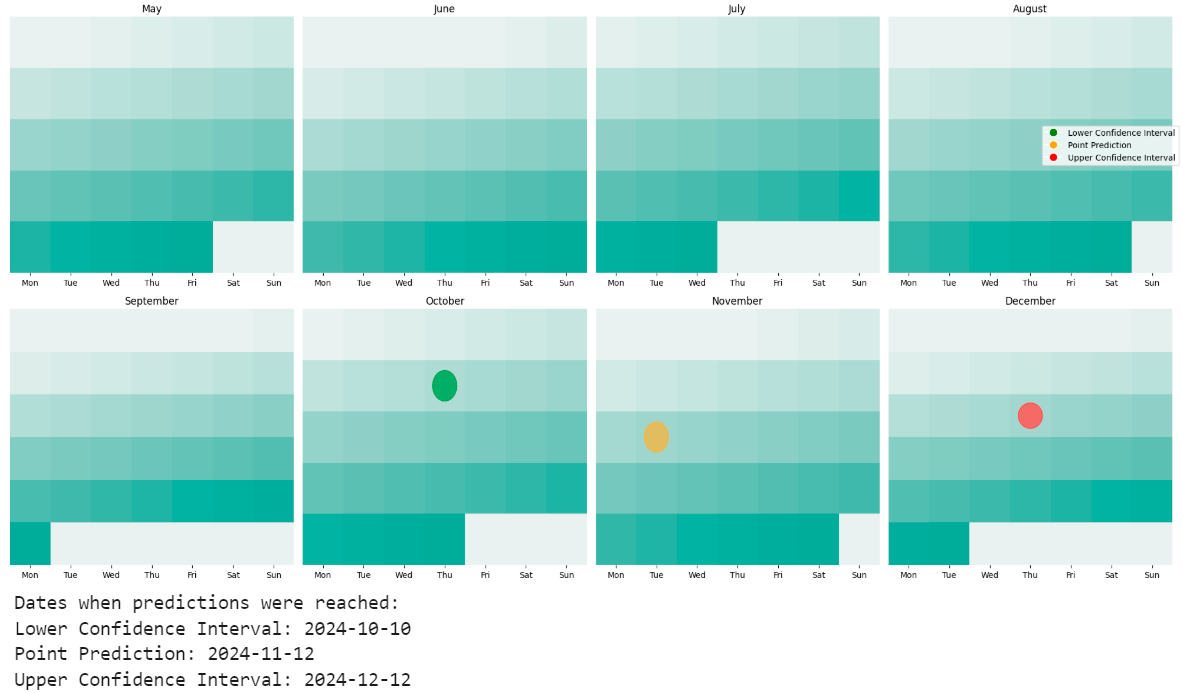
Let’s review the forecast a little to be more specific: our upper confidence interval last year was 38717, and our lower one was 30583, with our prediction at 34650. One way to think about that is what day of the year the published CVEs surpassed our predictions.
If we exceed our upper confidence interval in August, I might be quite worried, but hitting it a couple weeks into December is actually quite comforting, despite the difference of ~2000 CVEs from our upper confidence interval. So our point prediction was off by 6k, but out upper confidence interval wa sonly off by 2k.
Another way of looking at this is “what accounts for a difference of about 2-6k between this year and last year’s processes?”.
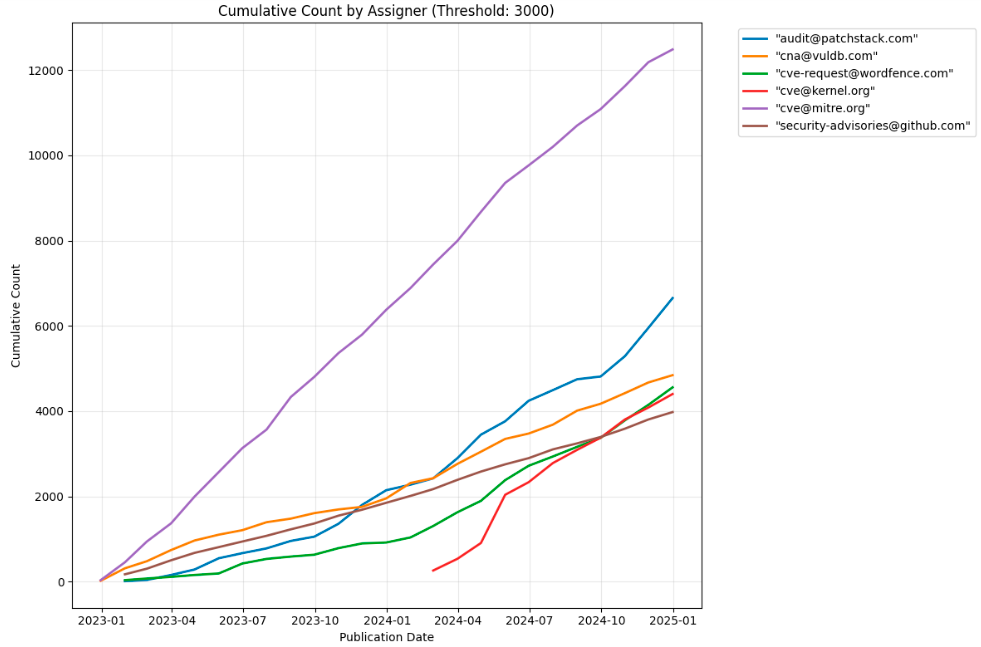
We can see here that a couple of CNAs (here called Assigners), have really ramped up their production of CVEs. Two in particular standout here as having a change of rate after we published the forecast, kernel.org and wordfence.
Wordfence simply increased its’ rate of production from about 1 thousand when we made our forecast to more than 4 thousand, but kernel.org really came out of the blue with more than 4 thousand vulnerabilities. Collectively that’s about 7 thousand vulnerabilities that would have been hard to predict back on New Year’s 2023.
This basically says to me, ‘the algorithm isn’t awful’, but perhaps we should look at the data and or calibration of the model to make better predictions. I’m slowly building out a team of volunteers to help with that, and you may see their names on these blog posts in the future.
As a review for why our yearly prediction was a bit off, I’m quite satisfied with this explanation. I don’t think we need to revisit the algorithm or parameterisation just yet, I’m convinced that the difference is explained by the data. So while a yearly prediction is expected to be wrong (by which we mean out of confidence intervals) every 1 in 10 years, I think this is simply that.
Before we forecasters are too hard on ourselves, it’s worth saying this is why we also publish a quarterly forecast as well. It allows us to update with new data instead of sticking dogmatically to an old forecast.
So how did our four quarterly forecasts go in 2024?
Quarter of 2024
Predicted
Actual
Within Confidence Intervals
Q1
8220
8905
Yes
Q2
8748
12011**
No
Q3
8841*
8659
Yes
Q4
9006
10909
No
Q3 was an experimental “step 2” forecast meaning that it was created by extrapolating on Q2’s prediction*. It is quite interesting to note that even when Q2 turned out to be wrong, it’s second order forecast was correct. I have no doubt this has something to do with Little’s Law, which simply means if you publish more from your backlog one quarter, then you will probably have a slower quarter afterwards.
There is one anomaly though, in that when I did the Q2 retrospective back in this blog post, I found it to be correct**. It’s only now in the yearly retrospective that it is wrong, and we discussed this phenomenon at our conference in Utrecht. Essentially, a number of publication dates were found to be wrong and corrected in Q3. This throws off the analysis and the forecasting algorithm in significant ways.
So in summary, while the data is changing underneath us it is difficult to be correct.
This highlights how the world relies on reliable information provided by NVD, Mitre, and CISA as an ecosystem that enables the attack surface and vulnerability management industries. It is worth mentioning that this whole ecosystem had a robust funding discussion this year, and a battle over who would publish data and how.
More generally there was an intentional if soft push for CNAs to "do more." This was directed at more information per record, not more records, but could have had an effect, in that those publishing richer CVEs may have also been able to create a change in their throughputs.
We will save next year’s forecast for a separate blog post, mostly because this one is already so long. However we think it is worth being publicly wrong and analysing it publicly in the aid of science and transparency. I encourage all the other vulnerability forecasters of the world to re-examine their predictions publicly as well.
We think forecasting vulnerabilities is fun and hard, and communicating clearly about success and failures is important. We hope that comes through here in this post where we asked ‘why were we wrong’. We also think the diversity of the CVE ecosystem will make this continually harder, but the need for predictive vulnerability information will only grow. In other words, the more vulnerabilities we’ll need to manage year on year makes forecasts even more useful, even when they’re wrong. In the immortal words of George Box “All models are wrong, but some are useful.”
We aim to make our forecasts useful and usable, and your feedback helps us do that, especially when they are wrong.
Eireann Leverett and the FIRST.org Vulnerability Forecasting Team
FIRST runs a blog open to members and invited guest authors. It publishes contributions relevant to incident responders. Articles should focus on general topics interesting to members. It will not be used to promote individual organisations, products or services. If you are interested in contributing, please get in touch with first-blog@first.org.
Learn more about the Forum of Incident Response and Security Teams through regular blog posts about our organization, events and other programs. Questions or comments? Contact first-press@first.org.